一、项目背景与目标
随着互联网信息的爆炸式增长,获取特定领域的专家信息(如高校导师信息)对于学术研究、企业合作及学生报考等具有重要意义。本项目旨在通过Python网络爬虫技术,系统性地爬取山东大学机械工程学院官网上的所有导师完整信息,包括但不限于姓名、职称、研究方向、联系方式、教育背景、学术成果等,并将其结构化存储。作为网页制作及网络工程技术咨询服务的一部分,本文将探讨在合法合规的前提下,如何高效、稳定地完成此类数据采集任务,并为相关技术需求提供解决方案。
二、技术选型与准备工作
- 核心工具:Python 3.x,因其丰富的库生态系统,是网络爬虫开发的首选。
- 关键库:
requests/aiohttp:用于发送HTTP请求,获取网页HTML内容。aiohttp支持异步,适合大规模页面抓取以提高效率。
BeautifulSoup/lxml:用于解析HTML/XML文档,提取所需数据。
pandas:用于数据清洗、整理和存储(如导出为CSV或Excel文件)。
re:正则表达式库,辅助提取复杂文本信息。
- 环境配置:确保安装上述库,可使用pip命令进行安装。
- 法律与道德考量:在爬取前,务必查看目标网站的
robots.txt文件(通常位于网站根目录,如https://www.mech.sdu.edu.cn/robots.txt),尊重网站的爬虫协议。避免过高频率的请求,以防对服务器造成压力,建议设置请求间隔(如使用time.sleep())。仅收集公开信息,不用于商业牟利或恶意用途。
三、爬虫设计与实现步骤
- 页面分析:
- 访问山东大学机械工程学院官网,找到导师信息页面(通常位于“师资队伍”或“教师名录”栏目)。
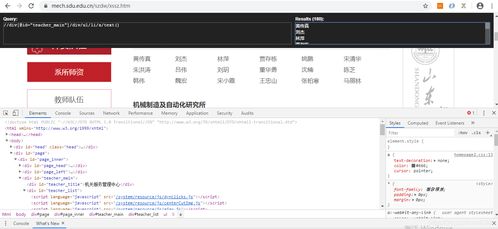
- 分析页面结构:确定是静态页面还是动态加载(如通过JavaScript)。可通过浏览器开发者工具(F12)查看网络请求,若数据通过XHR/Fetch请求获取,则需分析API接口。
- 假设为静态页面,使用
requests.get()获取HTML,并用BeautifulSoup解析。
- 数据提取:
- 定位导师列表的HTML元素(如
<div class="teacher-list">或<table>),提取每个导师的详情页链接或直接信息。
- 遍历每个导师条目,进一步访问详情页以获取完整信息。
- 编写解析函数,使用CSS选择器或XPath提取字段,例如:
`python
name = soup.selectone('.teacher-name').text.strip()
researcharea = soup.select_one('.research-field').text.strip()
`
- 数据存储:
- 将提取的数据暂存为字典或列表,最终使用
pandas.DataFrame转换为表格。
- 导出为CSV文件,如
sdu<em>mech</em>teachers.csv,便于后续分析或导入数据库。
- 异常处理与优化:
- 添加
try-except块处理网络超时、页面不存在等异常。
- 使用User-Agent头部模拟浏览器访问,避免被屏蔽。
- 考虑使用代理IP池和异步请求(如
aiohttp+asyncio)以提升爬取速度。
四、网页制作与网络工程技术咨询服务
在完成数据爬取后,这些信息可应用于多种场景,本咨询服务可提供以下支持:
- 数据展示网站开发:基于爬取的导师信息,构建一个交互式网页,实现搜索、筛选和详情查看功能。技术栈可包括HTML/CSS/JavaScript前端,以及Flask或Django后端框架,结合数据库(如MySQL或SQLite)存储数据。
- API接口设计:将数据封装为RESTful API,供第三方应用调用,便于集成到学术平台或移动应用中。
- 网络工程优化:针对爬虫项目,提供服务器部署、反爬虫策略规避、分布式爬虫设计等咨询服务,确保长期稳定运行。
- 数据安全与合规:指导如何加密存储敏感信息(如联系方式),并遵循GDPR等数据保护法规。
- 维护与更新:设计定时爬虫任务(如使用
cron或Celery),定期更新导师信息,保持数据时效性。
五、
本项目展示了如何利用Python爬虫技术从山东大学机械工程学院官网获取导师信息,并提供了从数据采集到应用开发的完整技术链。在实际操作中,需持续关注网站结构变化,调整爬虫代码。网页制作及网络工程技术咨询服务可帮助用户将原始数据转化为有价值的产品,提升信息利用效率。通过合法合规的技术手段,我们能够促进学术资源的共享与创新。
注意:本文为技术指导,具体实施时请确保获得相关网站许可,并遵守法律法规。如有疑问,可联系专业网络工程团队进行咨询。